FindingDory: A Benchmark to Evaluate Memory in Embodied Agents
Abstract
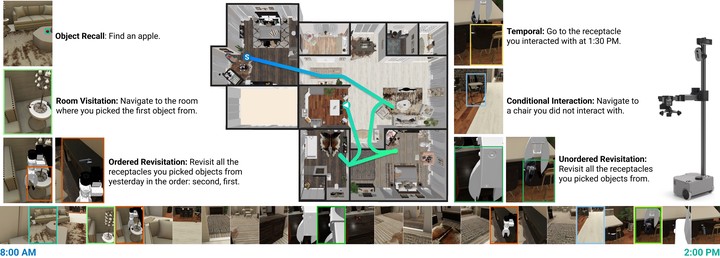
Large vision-language models have recently demonstrated impressive performance in planning and control tasks, driving interest in their application to real-world robotics. However, their deployment for reasoning in embodied scenarios is constrained due to difficulties incorporating long-term experiences spanning multiple days. Current VLMs typically struggle to process more than a few hundred images concurrently, highlighting the need for more efficient mechanisms to handle long-term memory in embodied settings. To effectively evaluate these models for long-horizon control, a benchmark must specifically target scenarios where memory is crucial for success. Existing video QA benchmarks lack crucial embodied challenges like object manipulation and navigation, which necessitate low-level skills and detailed reasoning about past actions. Effective memory use in embodied agents also requires integrating recall of historical information with immediate action execution. In this work, we introduce a new benchmark for long-range embodied tasks in the Habitat simulator. This benchmark evaluates memory-based capabilities across 57 tasks requiring sustained engagement and contextual awareness in an environment. The tasks can also be procedurally extended to longer and more challenging versions, enabling scalable evaluation of memory and reasoning. We also present baselines that integrate state-of-the-art VLMs with low level navigation policies, assessing their performance on these memory-intensive tasks and highlight areas for improvement.
Gunshi Gupta
Deep Learning Researcher
My research interests include Meta-Learning, Bayesian and Continual Deep Learning, Robotics.